
CVPR 2025 AI4CC Oral (Best Presentation)
*Brown Univeristy, †Equal Contribution
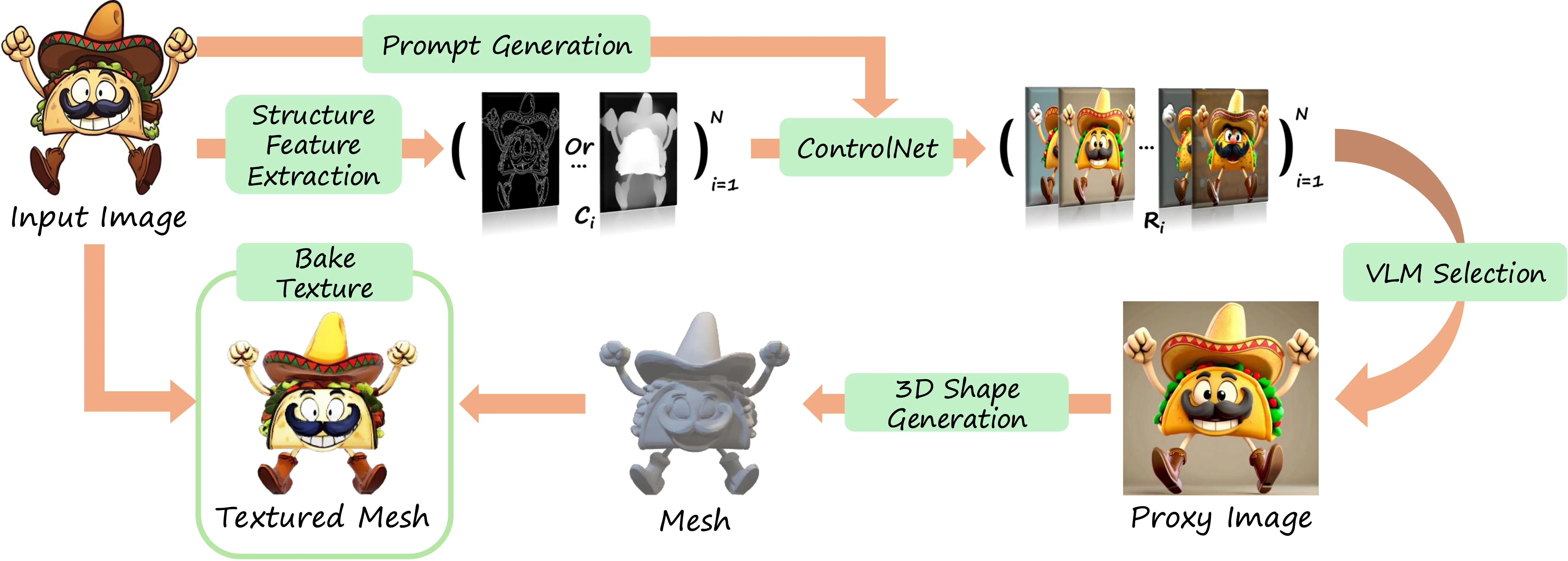
Large-scale pre-trained image-to-3D generative models have exhibited remarkable capabilities in diverse shape generations. However, most of them struggle to synthesize plausible 3D assets when the reference image is flat-colored like hand drawings due to the lack of 3D illusion, which are often the most user-friendly input modalities in art content creation. To this end, we propose Art3D, a training-free method that can lift flat-colored 2D designs into 3D. By leveraging structural and semantic features with pre- trained 2D image generation models and a VLM-based realism evaluation, Art3D successfully enhances the three-dimensional illusion in reference images, thus simplifying the process of generating 3D from 2D, and proves adaptable to a wide range of painting styles. To benchmark the generalization performance of existing image-to-3D models on flat-colored images without 3D feeling, we collect a new dataset, Flat-2D, with over 100 samples. Experimental results demonstrate the performance and robustness of Art3D, exhibiting superior generalizable capacity and promising practical applicability.


@misc{cong2025art3dtrainingfree3dgeneration,
title={Art3D: Training-Free 3D Generation from Flat-Colored Illustration},
author={Xiaoyan Cong and Jiayi Shen and Zekun Li and Rao Fu and Tao Lu and Srinath Sridhar},
year={2025},
eprint={2504.10466},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.10466},
}![Trellis [Xiang 2024]](/_astro/p_trellis.DdgkriiC.png)

![LGM [Tang 2024]](/_astro/dog_lgm.Cm6Gfm5u.png)

![InstantMesh [Xu 2024]](/_astro/fox_instantmesh.CsY7CFt0.png)

![3DTopia-XL [Chen 2024]](/_astro/man_3dtopia.B529VO-x.png)

![LN3Diff [Lan 2024]](/_astro/boy_ln3diff.Bzr3kIL_.png)

![Shap-E [Jun 2023]](/_astro/r_shape.BMIVUdj_.png)
